En los últimos meses he tenido la dicha de trabajar con la tecnología Entity Framework del ADO.NET de Microsoft. Debo decir que el paradigma de Code-First es una maravilla… es adictivo y te hace sentir en total control del modo en que se almacenan los datos del sistema que se esté diseñando/implementando.
Sin embargo tiene una limitante importante: cuando hay que sembrar la base de datos (Seed) con información para tablas maestras, y dicha información tiene un volumen importante de registros o datos, entonces tanto el mismísimo Visual Studio como el Entity Framework fallan. En mi caso, fue con intentar sembrar todos los códigos postales de España y Portugal… un poco más de 185.000 registros. El problema es esencialmente uno sólo: el número de registros a insertar es muy alto.
Kudos
Antes de empezar presentando la solución a este problema, me gustaria mencionar que el título de esta publicación es cortesía de mi esposa: Astrid a quien podéis seguir a través de Gikvanna en WordPress, Twitter y Facebook.
El Problema
Por un lado, con Code-First, debemos crear instancias de clases POCO que queremos insertar, pero cuando se tiene demasiados elementos, el Visual Studio se relentiza debido a que tiene que mantener constancia, integridad y estilo de los elementos que escribimos. No importa cuanta memoria o capacidad de procesamiento tenga nuestro equipo de trabajo… el Visual Studio se pondrá denso y pesado.
/// <summary>
/// Permite aplicar configuraciones a una base de datos.
/// </summary>
internal class DatabaseInitializer : IDatabaseInitializer<DatabaseContext>
{
...
/// <summary>
/// Agrega datos al contexto (<see cref="DatabaseContext"/>) para <i>sembrarlo</i>.
/// </summary>
/// <param name="context">El contexto a sembrar.</param>
protected override void Seed(DatabaseContext context)
{
...
// Códigos postales para el 'seed'.
List<PostalCode> = new List<PostalCode>
{
// Más de 185.000 registros de esta misma forma.
new PostalCode { Value="pc1", AlternativeId="cp1" },
new PostalCode { Value="pc2", AlternativeId="cp2" },
new PostalCode { Value="pc3", AlternativeId="cp3" },
new PostalCode { Value="pc4", AlternativeId="cp4" },
new PostalCode { Value="pc5", AlternativeId="cp5" },
new PostalCode { Value="pc6", AlternativeId="cp6" },
...
}
...
}
...
}
Por otro lado cuando intentemos iniciar la aplicación por primera vez (sin base de datos alguna), el tiempo de creación de ésta junto al sembrado es tan alto y el número de INSERTs tan elevado que se producen muchos time-outs (tanto en la base de datos como en el servidor web en caso de aplicaciones de este tipo); lo cual hace el proceso de desarrollo e implementación muy frustrante.
Una Alternativa de Solución
El primer problema, referente al número elevado de instancias de la clase POCO que debemos crear para el sembrado, se soluciona fácilmente almacenando los datos en archivos de texto o de recursos en un formato parseable, como por ejemplo un listado de elementos separados por coma.
private static IList<PostalCode> ReadPostalCodes()
{
// Leer los códigos postales desde recursos 'embebidos' (empotrados) en el ensamblado (assembly).
Assembly currentAssembly = Assembly.GetExecutingAssembly();
IEnumerable<string> postalCodesResourceFileNames = currentAssembly.GetManifestResourceNames().Where(resourceName => resourceName.Contains("PostalCodes_"));
Stream stream = null;
string[] itemTokens = null;
IList<PostalCode> postalCodes = new List<PostalCode>();
foreach (string postalCodeResourceFileName in postalCodesResourceFileNames)
{
try
{
stream = currentAssembly.GetManifestResourceStream(postalCodeResourceFileName);
using (StreamReader streamReader = new StreamReader(stream))
{
// Cada dato está separado por un salto de línea, y a su vez, cada elemento de cada dato está separado por comas.
IEnumerable<string> postalCodeItems = streamReader.ReadToEnd().Split(new string[] { "\r\n" }, StringSplitOptions.RemoveEmptyEntries);
foreach (string postalCodeItem in postalCodeItems)
{
itemTokens = postalCodeItem.Split(new char[] { ',' }, StringSplitOptions.RemoveEmptyEntries);
postalCodes.Add(new PostalCode { Country = itemTokens[0], Value = itemTokens[1] });
}
}
}
finally
{
if (stream != null)
{
stream.Dispose();
}
}
}
return postalCodes;
}
Para resolver el segundo problema, referente a la inserción de un elevado número de registros, nos apoyaremos en una clase del Framework .NET llamada SqlBulkCopy, la cual toma un DataTable o un IDataReader para realizar una inserción masiva de datos en la base de datos.
En los siguientes códigos fuentes, los comentarios estarán en inglés tal y como los tengo en mis proyectos, y que por diversas razones no he tenido tiempo de traducirlos al Castellano. Eventualmente trataré de ir editando esta publicación para traducirlas poco a poco.
La idea es entonces integrar la clase DbContext empleada en Entity Framework para interactuar con el repositorio de datos a través la clase SqlBulkCopy. Esta integración es fácilmente alcanzable con métodos de extensión que permitan emplear el método de inserción con cualquier DbContext; por lo cual el primer paso es crear la clase estática (con los respectivos using que necesitaremos a lo largo de la solución).
using System;
using System.Collections.Generic;
using System.Data;
using System.Data.Entity;
using System.Data.Entity.Infrastructure;
using System.Data.Metadata.Edm;
using System.Data.Objects;
using System.Data.SqlClient;
using System.Globalization;
using System.Linq;
using System.Reflection;
namespace My.Data.Entity
{
/// <summary>
/// Contains extensions method for <see cref="DbContext"/> objects that works specifically with Microsoft SQL Server databases.
/// </summary>
public static class DbContextSqlServerExtensions
{
...
}
}
Dentro de esta clase crearemos el método de extensión BulkInsert para inserción masiva, junto con una sobre carga cuyo objetivo explicaré más adelante. Como podréis ver, el método carece prácticamente de toda lógica más allá de invocar a otro método llamado ExecuteBulkInsert el cual será el verdadero responsable de realizar la lógica de inserción masiva apoyado en la clase SqlBulkCopy.
Sin embargo, igual en la documentación hacemos incapié en una advertencia muy importante que también debemos tomar en cuenta: en esta solución se emplea Reflection para acceder a métodos y propiedades de las clases de Entity Framework que para la versión actual (no beta) disponible a la fecha de esta publicación, correspondiente a la 5.0, son internal y no públicas (public) en el API. Esto significa que esta solución puede dejar de funcionar, o no funcionar como se espera cuando se emplee con nuevas versiones de Entity Framework que puedan haber modificado el comportamiento sistémico de las propiedades y métodos invocados a través de Reflection.
/// <summary>
/// <para>
/// Performs a bulk load of a collection of entities into a database, and regenerates the entity list with updated
/// information.
/// </para>
/// <para>
/// Due to some technological limitations, the regeneration of the list is actually a retrieval of fresh data from
/// storage (database) with all the available entities, in other words, it will get all the entities from storage
/// and not only those in the original entity list.
/// </para>
/// </summary>
/// <remarks>
/// <para>
/// This method leverages the <see cref="SqlBulkCopy "/> class and the <c>BCP</c> protocol to insert a collection
/// of entities into the storage configured in the <see cref="DbContext"/> parameter.
/// </para>
/// <para>
/// <b><u>WARNING:</u></b> This method relays on <a href="http://msdn.microsoft.com/en-us/library/ms173183(v=vs.100).aspx"><c>Reflection</c></a>
/// to retrieve values from properties that are not <c>public</c> (in fact, properties that are <c>internal</c> or <c>private</c>).
/// This means that there is a possible risk that this method will break, stop working or not-working as expected when new versions of
/// Entity Framework are released by Microsoft.
/// </para>
/// </remarks>
/// <typeparam name="TEntity">The type of entity to insert.</typeparam>
/// <param name="context">
/// The context to work with. This context must have configured a connection to a storage (like a database).
/// </param>
/// <param name="list">
/// A collection of entities to insert.This reference might be reloaded it with updated entities
/// if the <paramref name="reloadEntities"/> parameter is set to <c>true</c>.
/// </param>
/// <param name="reloadEntities">
/// Determines if the entities list must be reloaded with updated entities from storage. If <c>true</c> the entities are
/// going to be reloaded and stored in the list passed as parameter, otherwise <c>false</c> and the entities are not going
/// to be reloaded.
/// </param>
public static void BulkInsert<TEntity>(this DbContext context, IList<TEntity> list, bool reloadEntities) where TEntity : class
{
ExecuteBulkInsert<TEntity>(context, ref list, reloadEntities);
}
Como puede apreciarse, el método BulkInsert posee dos (2) sobre cargas: la primera simplemente considera una colección (en forma de lista) de las entidades (objetos de las clases POCO) a insertar mientras que la segunda toma un valor booleano que corresponde a un indicador de si deseamos recargar las entidades una vez insertadas, lo cual puede resultar muy útil para obtener nuevamente estas entidades pero con las propiedades correspondientes a las claves primaras en el repositorio de datos apropiadamente establecidas (de ahí que el método ExecuteBulkInsert reciba la colección/lista de entidades como un parámetro ref).
/// <summary>
/// Actually executes the bulk load of a collection of entities into a database, and regenerates the entity list with updated
/// information, if required.
/// </summary>
/// <typeparam name="TEntity">The type of entity to insert.</typeparam>
/// <param name="context">
/// The context to work with. This context must have configured a connection to a storage (like a database).
/// </param>
/// <param name="list">
/// A collection of entities to insert.This reference might be reloaded it with updated entities if
/// the <paramref name="reloadEntities"/> parameter is set to <c>true</c>. It is received as <c>ref</c>
/// in order to warranty the reload.
/// </param>
/// <param name="reloadEntities">
/// Determines if the entities list must be reloaded with updated entities from storage. If <c>true</c> the entities are
/// going to be reloaded and stored in the list passed as parameter, otherwise <c>false</c> and the entities are not going
/// to be reloaded.
/// </param>
private static void ExecuteBulkInsert<TEntity>(DbContext context, ref IList<TEntity> list, bool reloadEntities) where TEntity : class
{
Type typeOfEntity = typeof(TEntity);
ObjectContext objectContext = ((IObjectContextAdapter)context).ObjectContext;
// Retrieve the Storage Data Space for the entity we are working with. From it, get the members which represents the columns in the database. From
// those members, we can get the real name of the columns (since the developer may have changed them with the 'HasColumnName' method) and their types.
ReadOnlyMetadataCollection<EdmMember> storageSpaceMembers = objectContext.MetadataWorkspace.GetItem<EntityType>(@"CodeFirstDatabaseSchema." + typeOfEntity.Name, DataSpace.SSpace).Members;
using (SqlBulkCopy sqlBulkCopy = new SqlBulkCopy(context.Database.Connection.ConnectionString))
{
using (DataTable dataTable = new DataTable())
{
dataTable.Locale = CultureInfo.InvariantCulture;
// For each column defined in the Storage Data Space...
for (int index = 0; index < storageSpaceMembers.Count; index++)
{
// ...configure the instance of the SqlBulkCopy class with the name of the source and destination column...
sqlBulkCopy.ColumnMappings.Add(storageSpaceMembers[index].Name, storageSpaceMembers[index].Name);
// ...and also configure a DataTable with the name of the column and its respective CLR type.
/**************************************************************************************************************
* This is the risky part of the code. From this point on, the properties and methods employed are invoked by *
* Reflection and are non-public (i.e. internal) in the Entity Framework assembly. *
**************************************************************************************************************/
/*****************************************************************************************************************
* WARNING: the 'ClrType' property is not public; actually, it is 'internal virtual'. This means that there is a *
* possible risk that this method will break, stop working or not working as expected when new versions of *
* Entity Framework are released by Microsoft. *
*****************************************************************************************************************/
dataTable.Columns.Add(storageSpaceMembers[index].Name, GetPropertyValue<Type>(storageSpaceMembers[index].TypeUsage.EdmType, @"ClrType"));
}
PopulateDataTable(dataTable, objectContext, list, storageSpaceMembers);
sqlBulkCopy.DestinationTableName = GetTableName(objectContext, typeOfEntity);
sqlBulkCopy.BatchSize = list.Count;
sqlBulkCopy.WriteToServer(dataTable);
}
}
if (reloadEntities)
{
list = context.Set<TEntity>().ToList();
}
}
El primer paso consiste en obtener el nombre real de las columnas que se corresponden a las propiedades de la entidad que deseamos insertar, el cual en principio no debería diferir mucho de dichas propiedades, pero que ciertamente puede haber cambiado si el programador ha empleado el método HasColumnName al configurar como se almacenaría la entidad en el repositorio de datos.
Para obtener los nombres de las columnas, se realiza una búsqueda en la metadata del contexto obteniendo de ésta todos los objetos que existan en el modelo de almacenamiento cuyo nombre se corresponda al nombre de la entidad a insertar precedido del nombre del esquema por defecto para desarrollos con Code First: CodeFirstDatabaseSchema.
Con los nombres de las columnas se puede crear la instancia de la clase SqlBulkCopy a usar, configurando ésta con los nombres de la columna origen y la columna destino. Así mismo, se crea y configura una instancia de la clase DataTable que se empleará con el SqlBulkCopy para realizar la inserción. Sin embargo, el DataTable requiere conocer el tipo de dato exacto y concreto de la columna, para lo cual es necesario invocar al método internal virtual ClrType de la clase EdmMember obtenida del modelo de almacenamiento de la metadata a través de Reflection.
Una vez configurada la instancia del DataTable es necesario poblarla con los valores apropiados, para lo cual empleamos el método auxiliar PopulateDataTable.
/// <summary>
/// Fills a <see cref="DataTable" /> with data from a list of entities.
/// </summary>
/// <remarks>
/// <para>
/// This method is an auxiliary method for the <see cref="DbContextExtensions.BulkInsert{TEnity}(DbContext, ref IList{TEnity}, bool)"/> method.
/// </para>
/// <para>
/// The <c>storageSpaceMembers</c> parameter is just a performance consideration. It is previously retrieved in the
/// <see cref="DbContextExtensions.BulkInsert{TEnity}(DbContext, ref IList{TEnity}, bool)"/> method, and in order to not calculate it again, it is passed as
/// parameter to this method. However, this can be changed if improvement of the isolation of this method is required.
/// </para>
/// </remarks>
/// <typeparam name="TEnity">The type of entity used to fill the <see cref="DataTable"/>.</typeparam>
/// <param name="dataTable">The <see cref="DataTable"/> to fill.</param>
/// <param name="objectContext">A context to perform operation on the entities. </param>
/// <param name="list">The list of entities used to fill the <see cref="DataTable"/>.</param>
/// <param name="storageSpaceMembers">A list of members for the entity type on the Storage Data Space.</param>
private static void PopulateDataTable<TEnity>(DataTable dataTable, ObjectContext objectContext, IList<TEnity> list, ReadOnlyMetadataCollection<EdmMember> storageSpaceMembers) where TEnity : class
{
Type typeOfEntity = typeof(TEnity);
// Get the Object Space, which contains data and information of the current model (classes and members).
ReadOnlyMetadataCollection<EdmMember> objectSpaceMembers = objectContext.MetadataWorkspace.GetItem<EntityType>(typeOfEntity.FullName, true, DataSpace.OSpace).Members;
EntitySetBase entitySetBase = objectContext.MetadataWorkspace.GetEntityContainer(objectContext.DefaultContainerName, DataSpace.CSpace).BaseEntitySets.FirstOrDefault(baseEntitySet => baseEntitySet.ElementType.Name.Equals(typeOfEntity.Name, StringComparison.OrdinalIgnoreCase));
EntityType entityType = (EntityType)entitySetBase.ElementType;
foreach (TEnity entity in list)
{
DataRow dataRow = dataTable.NewRow();
// For each property of the entity, retrieve its value and assign it to the appropriate corresponding column of the DataTable.
foreach (EdmProperty edmProperty in entityType.Properties)
{
// To obtain the appropriate column, We use a combination of the Storage Data Space with the Object Space.
// - First: obtain from the Object Space the property that matches the name of the entity property being populated in the DataTable.
// - Second: get the index of the property from the Object Space. This index or position in the Object Space is going to be the same
// in all other spaces, including the Storage Data Space.
// - Third: with this index, retrieve the corresponding property in the Storage Data Space.
// - Fourth: from the retrieved property in the Storage Data Space, get its name which will correspond to the column name in the DataTable.
// - Fifth: by 'Reflection' get the value of the property and assign it to the DataTable.
dataRow[storageSpaceMembers[objectSpaceMembers.IndexOf(objectSpaceMembers[edmProperty.Name])].Name] = GetPropertyValue<object>(entity, edmProperty.Name);
}
// Get the appropriate value of any referencial constraint (like a foreign key).
if (entityType.NavigationProperties.Count > 0)
{
ICollection<ReferentialConstraint> referentialConstraints = GetReferentialConstraints(objectContext, typeOfEntity, entitySetBase);
foreach (NavigationProperty navigationProperty in entityType.NavigationProperties)
{
// Filter the referencial contraints to get only those that apply to the entity being manipulated.
// Only the "From Role" part of the relationship is required since We are inserting the "To Role" part.
IEnumerable<ReferentialConstraint> filteredReferentialConstraints = referentialConstraints.Where(referentialConstraint => referentialConstraint.FromRole.Name.Equals(navigationProperty.Name, StringComparison.OrdinalIgnoreCase));
foreach (ReferentialConstraint referentialConstraint in filteredReferentialConstraints)
{
dataRow[referentialConstraint.ToProperties[0].Name] = GetPropertyValue<object>(GetPropertyValue<object>(entity, referentialConstraint.FromRole.Name), referentialConstraint.FromProperties[0].Name);
}
}
}
dataTable.Rows.Add(dataRow);
}
}
Este método se encargará de combinar la información del espacio del modelo de almacenamiento con la información del espacio del modelo de objetos de la metadata del contexto para mapear cada propiedad con la columna correspondiente y asignar el valor respectivo. El truco aquí es darse cuenta que la indexación entre los diferentes espacios de la metadata del contexto es la misma; así, un elemento en una específica posición del espacio de almacenamiento corresponderá al mismo elemento en la misma específica posición en cualquiera de los otros espacios (conceptual, de objectos, etc.).
Un aspecto importante de éste método es la determinación de las referencias (esto es, claves foráneas o secundarias) para obtener los valores que correspondan únicamente a la entidad siendo manipulada y evitar problemas de congruencia en los datos a insertar o excepciones de Entity Framework debido a éstas. Por cada elemento de restricción referencial, se busca la propiedad que le corresponde y por tanto la columna respectiva en el DataTable para asignar su valor.
Estas restricciones referenciales se determinan a través de una invocación al método auxiliar GetReferentialConstraints, el cual toma el contexto de datos siendo empleado, el tipo de la entidad (esto es, el tipo del POCO) y un objeto denominado entity set base que se corresponde a la metadata que relaciona el modelo de almacenamiento con el modelo conceptual (del cual se extraen las referencias).
/// <summary>
/// Retrieves a collection of <see cref="ReferentialConstraint"/> elements for a given entity type (and entity set base)
/// on the current object context.
/// </summary>
/// <remarks>
/// <b><u>WARNING:</u></b> This method relays heavily on <a href="http://msdn.microsoft.com/en-us/library/ms173183(v=vs.100).aspx"><c>Reflection</c></a>
/// to retrieve the referential constraints information because it is hidden in the Entity Framework assembly (i.e. <c>internal</c> types and members).
/// Starting with the retrieval of the mapping between the conceptual model and the storage model (<see cref="DataSpace.CSSpace"/>) everything in the
/// obtained <see cref="ItemCollection"/> is non-public. This means that there is a possible risk that this method will break, stop working or
/// not-working as expected when new versions of Entity Framework are released by Microsoft.
/// </remarks>
/// <param name="objectContext">Object context to work with.</param>
/// <param name="entityType">Type of the entity whose referential constraints are going to be retrieved.</param>
/// <param name="entitySetBase">Entity base with the information of referential constraints to retrieve.</param>
/// <returns>A collection of referential constraints for the given entity in the current object context.</returns>
private static ICollection<ReferentialConstraint> GetReferentialConstraints(ObjectContext objectContext, Type entityType, EntitySetBase entitySetBase)
{
List<ReferentialConstraint> referentialConstraints = new List<ReferentialConstraint>();
// Get the data space that contains the mapping between the conceptual model and the storage model.
GlobalItem conceptToStorageItemCollection = objectContext.MetadataWorkspace.GetItemCollection(DataSpace.CSSpace).First();
/**************************************************************************************************************
* This is the risky part of the code. From this point on, the properties and methods employed are invoked by *
* Reflection and are non-public (i.e. internal) in the Entity Framework assembly. *
**************************************************************************************************************/
// - First: get the entity set mapping (System.Data.Mapping.StorageSetMapping class) from the data space that maps
// the conceptual model and the storage model by invoking the internal 'GetEntitySetMapping' method.
//
// - Second: get the collection of type mappings (a System.Collections.ObjectModel.ReadOnlyCollection of System.Data.Mapping.StorageSetMapping objects)
// from the entity set mapping with the 'TypeMappings' property. Since the collection elements is internal it will be 'unknow'
// to the compiler during design time, so it's marked as dynamic.
dynamic dynamicStorageTypeMappings = GetPropertyValue<dynamic>(conceptToStorageItemCollection.GetType().GetMethod("GetEntitySetMapping", BindingFlags.NonPublic | BindingFlags.Instance).Invoke(conceptToStorageItemCollection, new object[] { entitySetBase.Name }), "TypeMappings");
foreach (object storageTypeMapping in dynamicStorageTypeMappings)
{
// - Third: for each type mapping, get the mapping fragments (a System.Collections.ObjectModel.ReadOnlyCollection of System.Data.Mapping.StorageMappingFragment
// objects). Each mapping fragment provides information and data for those properties of a type that map to a single table.
dynamic dynamicStorageMappingFragments = GetPropertyValue<dynamic>(storageTypeMapping, "MappingFragments");
foreach (object storageMappingFragment in dynamicStorageMappingFragments)
{
// - Fourth: get an entity set that represents a table from which the properties are mapped in this fragment by invoking the 'TableSet' property.
EntitySet tableSet = GetPropertyValue<EntitySet>(storageMappingFragment, "TableSet");
// Fifth: just verify the table set is not empty and its name corresponds to the entity we are working with.
if (tableSet != null && tableSet.Name.Equals(entityType.Name, StringComparison.OrdinalIgnoreCase))
{
// - Sixth: get a collection of tuples of assosiation sets and referencial contraints from the table set by invoking the internal
// property 'ForeignKeyDependents'.
//
// - Seventh: from such collection, get only the referencial contraints items and add them to the collection we are going to
// return as result of this method.
referentialConstraints.AddRange(GetPropertyValue<ICollection<Tuple<AssociationSet, ReferentialConstraint>>>(tableSet, "ForeignKeyDependents").Select(foreignKeyDependent => foreignKeyDependent.Item2));
}
}
}
return referentialConstraints;
}
Este método es el más delicado de todos, ya que es el que más propiedades y métodos private o internal del Entity Framework invoca a través de Reflection. Básicamente, todo lo que se invoca tras obtener la información de la metadata que relaciona el modelo conceptual con el modelo de almacenamiento es o bien internal o bien private. Por otro lado, otro reto es que los tipos del mapeo entre el modelo conceptual y el de almacenamiento no son conocidos, por lo cual deben ser tratados como dynamic. Lo que se hace con estos objetos es buscar aquellos que tienen relación con la entidad que se está insertando para identificarlos como referencias con ésta y conservarlas en una colección que retornaremos al llamador responsable de poblar el DataTable.
Finalmente, nuevamente en el método ExecuteBulkInsert se establece el nombre de la tabla (entidad) a poblar con el SqlBulkCopy, el número de registros y los registros en si.
¡Y ESO SERÍA TODO!
Al ejecutar mi solución sin la base de datos, el proceso de crearla y poblarla (sembrarla) con los códigos postales de España y Portugal (que como hemos mencionado es un número superior a 185.000 registros) tarda algo menos de… ¡¡¡dos milisegundos!!! No hay time/outs ni fallos de ningún tipo.
Más detalles de la implementación en los comentarios de los propios métodos que he dejado como parte del código fuente expuesto en esta publicación. Se que están en inglés, pero los tengo así por temas de mi trabajo del día a día. Sin embargo espero que podáis entenderlos y os aportén más luz sobre esta alternativa de solución.
Métodos Auxiliares
A lo largo de esta publicación, habrán visto referencias e invocaciones a métodos como GetPropertyValue o GetTableName. Dichos métodos no existen en el API del Framework .NET o del Entity Framework. Son métodos auxiliares que he creado para conseguir el objetivo de esta solución. En esta parte os dejo el código fuente de los mismos.
/// <summary>
/// Retrieves a the named property (public or not) from an object trough <c>Reflection</c>.
/// </summary>
/// <typeparam name="TValue">The type of the property to retrieve.</typeparam>
/// <param name="element">The object where to reflect the property.</param>
/// <param name="propertyName">The name of the property to retrieve.</param>
/// <returns>The value of the named property.</returns>
private static TValue GetPropertyValue<TValue>(object element, string propertyName) where TValue : class
{
return element.GetType().GetProperty(propertyName, BindingFlags.NonPublic | BindingFlags.Public | BindingFlags.Instance).GetValue(element, null) as TValue;
}
/// <summary>
/// Retrieves the name of the dataTable.
/// </summary>
/// <remarks>
/// Developers may change the name of the dataTable from the expected standard to a custom one by using
/// the <see cref="System.Data.Entity.ModelConfiguration.EntityTypeConfiguration{TEntityType}.ToTable(string)"/> method. This method will retrieve such configuration.
/// </remarks>
/// <param name="objectContext">The <see cref="ObjectContext"/> with mapping and concept model data.</param>
/// <param name="entityType">Type of the entity type configuration whose dataTable name is going to be retrieved.</param>
/// <returns>The configured name of the dataTable for the provided entity type configuration.</returns>
private static string GetTableName(ObjectContext objectContext, Type entityType)
{
return objectContext.MetadataWorkspace.GetItems<EntityContainer>(DataSpace.SSpace).FirstOrDefault().BaseEntitySets.FirstOrDefault(entityBaseSet => entityBaseSet.Name.Equals(entityType.Name, StringComparison.OrdinalIgnoreCase)).MetadataProperties[@"Table"].Value.ToString();
}
Otros Gestores de Bases de Datos
El Entity Framework soporta cualquier gestor de base de datos que implemente un conector para ADO.NET. Para el caso de esta solución y el uso de la clase SqlBulkCopy he asumido que se está usando Entity Framework con una base de datos Microsoft SQL Server. Sin embargo, si se quisiera usar un gestor como ORACLE, en vez de usar la clase SqlBulkCopy se tendría que usar las facilidades propias del ODP.NET como el Bulk Array (también conocido como ODP.NET Array Binding).

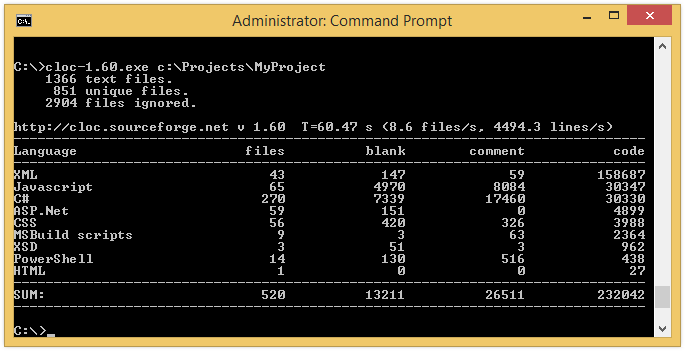
 Contar líneas de código fuente es una práctica que se viene realizando desde tiempos inmemoriales… vamos desde antes de 1970 más o menos. Por ejemplo, de acuerdo con el Centro Tecnológico de Calidad de Software (Software Assurance Technology Center – SATC) de la NASA:
Contar líneas de código fuente es una práctica que se viene realizando desde tiempos inmemoriales… vamos desde antes de 1970 más o menos. Por ejemplo, de acuerdo con el Centro Tecnológico de Calidad de Software (Software Assurance Technology Center – SATC) de la NASA: 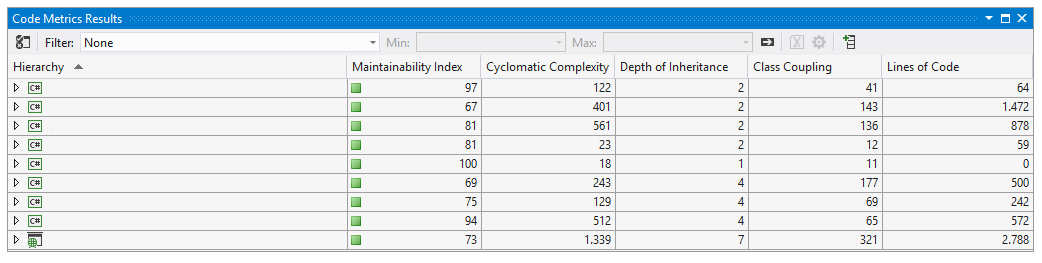

 Básicamente son programadores con un nivel de experiencia y una pasión efervescente, siempre encendida por nuestra disciplina. No sólo son ágiles, sino también disciplinados y centrados en su trabajo.
Básicamente son programadores con un nivel de experiencia y una pasión efervescente, siempre encendida por nuestra disciplina. No sólo son ágiles, sino también disciplinados y centrados en su trabajo. El programador Zen comparte algunas características con el programador Ninja, pero su principal diferencia es que, aunque son ágiles, no están orientados a entregar software de forma rápida. Se toman su tiempo, meditan y vuelven a meditar antes de tomar alguna acción.
El programador Zen comparte algunas características con el programador Ninja, pero su principal diferencia es que, aunque son ágiles, no están orientados a entregar software de forma rápida. Se toman su tiempo, meditan y vuelven a meditar antes de tomar alguna acción.